¿Cómo permitir crawlers sin exponerlo todo?
Reglas claras (robots/meta) + trade-offs
Ejemplos de robots/meta + escenarios
/guia/control-snippets-bots

Si ya estás “en la liga” (EEAT fuerte, arquitectura por clusters, rendimiento, rastreo saludable), tu cuello de botella no suele ser “rankear”: es ser elegido como fuente y ser recordado como entidad. El objetivo real en GEO/LLMO no es solo aparecer: es aparecer citado, de forma recurrente, cuando una IA construye una respuesta y necesita evidencia confiable. Una cita es un premio a la claridad, la verificabilidad y la consistencia. El resto (técnico, enlaces internos, contenido) ya lo haces: aquí afinamos lo que hace que una plataforma te seleccione como “evidencia” y no como “relleno”.
Purus suspendisse a ornare non erat pellentesque arcu mi arcu eget tortor eu praesent curabitur porttitor ultrices sit sit amet purus urna enim eget. Habitant massa lectus tristique dictum lacus in bibendum. Velit ut viverra feugiat dui eu nisl sit massa viverra sed vitae nec sed. Nunc ornare consequat massa sagittis pellentesque tincidunt vel lacus integer risu.
Mauris posuere arcu lectus congue. Sed eget semper mollis felis ante. Congue risus vulputate nunc porttitor dignissim cursus viverra quis. Condimentum nisl ut sed diam lacus sed. Cursus hac massa amet cursus diam. Consequat sodales non nulla ac id bibendum eu justo condimentum. Arcu elementum non suscipit amet vitae. Consectetur penatibus diam enim eget arcu et ut a congue arcu.

Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
Vitae vitae sollicitudin diam sed. Aliquam tellus libero a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulla aliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
“Nisi consectetur velit bibendum a convallis arcu morbi lectus aecenas ultrices massa vel ut ultricies lectus elit arcu non id mattis libero amet mattis congue ipsum nibh odio in lacinia non”
Nunc ut facilisi volutpat neque est diam id sem erat aliquam elementum dolor tortor commodo et massa dictumst egestas tempor duis eget odio eu egestas nec amet suscipit posuere fames ded tortor ac ut fermentum odio ut amet urna posuere ligula volutpat cursus enim libero libero pretium faucibus nunc arcu mauris sed scelerisque cursus felis arcu sed aenean pharetra vitae suspendisse ac.
Si ya haces SEO bien, el siguiente salto no es rankear: es construir evidencia y entidad para que la IA te elija como fuente
Si el SEO base está bien, normalmente faltan 3 cosas:
El SEO clásico te mete en el set competitivo: indexación, relevancia temática, autoridad, UX, enlazado interno. Pero las citas suelen exigir “extras”:
Una “cita de LLM” es una atribución visible (enlace, tarjeta de fuente, panel de referencias) que acompaña a una respuesta generativa. No es lo mismo que “ser usado” internamente: lo que optimizas aquí es ser mostrado como fuente.
Cuando ChatGPT usa búsqueda, selecciona páginas accesibles y legibles, extrae fragmentos y muestra enlaces como fuentes. En la práctica, aumentas probabilidad si tienes: (1) rastreo permitido para el crawler correcto, (2) contenido verificable y (3) una URL canónica que “represente” el concepto.
En Copilot, la atribución está integrada y pensada para que el usuario “vea fuentes” mientras consume un resumen. Eso cambia el KPI: tu marca puede ganar presencia aunque baje el clic; por eso necesitas medir visibilidad/citas además de sesiones.
Para AI Overviews/AI Mode, la guía útil es: no hay requisitos técnicos extra; aplica SEO base y contenido útil. Para ser elegible como enlace de apoyo, tu página debe estar indexada y ser elegible para snippet. Y los controles de snippet (nosnippet/data-nosnippet/max-snippet/noindex) también afectan lo que puede mostrarse.
Si tu baseline ya está, la palanca no es “más SEO”, sino subir la probabilidad de selección con un modelo mental simple:
Si bloqueas rastreo o snippets, te autoexcluyes de muchas experiencias generativas. Antes de tocar robots/antibot/CDN, define tu objetivo: discoverability (citas/links) vs restricciones.
OpenAI documenta crawlers y controles por user-agent: puedes permitir el bot orientado a “search” y bloquear el de “training” de forma independiente.
Checklist rápido (accesibilidad):
Un LLM cita lo que puede defender. Lo genérico compite por “redacción”; lo citable compite por “prueba”.
Patrón evidence-first:
Para que te citen recurrentemente, necesitas ser “el sitio de X” en la cabeza del sistema:
Para citas, suele funcionar mejor tener 3–6 URLs canónicas por tema (reference pages) y usar el resto del cluster como soporte (casos, long-tail, comparativas, actualizaciones). La IA necesita “una URL que represente el concepto” y que sea estable.
Modelo de set canónico por tema (ejemplo):
Cada H2/H3 debería abrir con 2–3 frases autocontenidas (citable), y luego el desarrollo.
Ejemplo de patrón:
Respuesta rápida: Si quieres que te citen, crea una URL canónica por concepto con definición + criterios + evidencia (fechas y fuentes), y enlázala desde todo el cluster.
Desarrollo: casos, matices, implementación, ejemplos.
Tabla operativa (plantilla que puedes adaptar):
Un sistema generativo penaliza (aunque sea implícitamente) lo que huele a “viejo” o “no verificable”.
Recomendaciones:
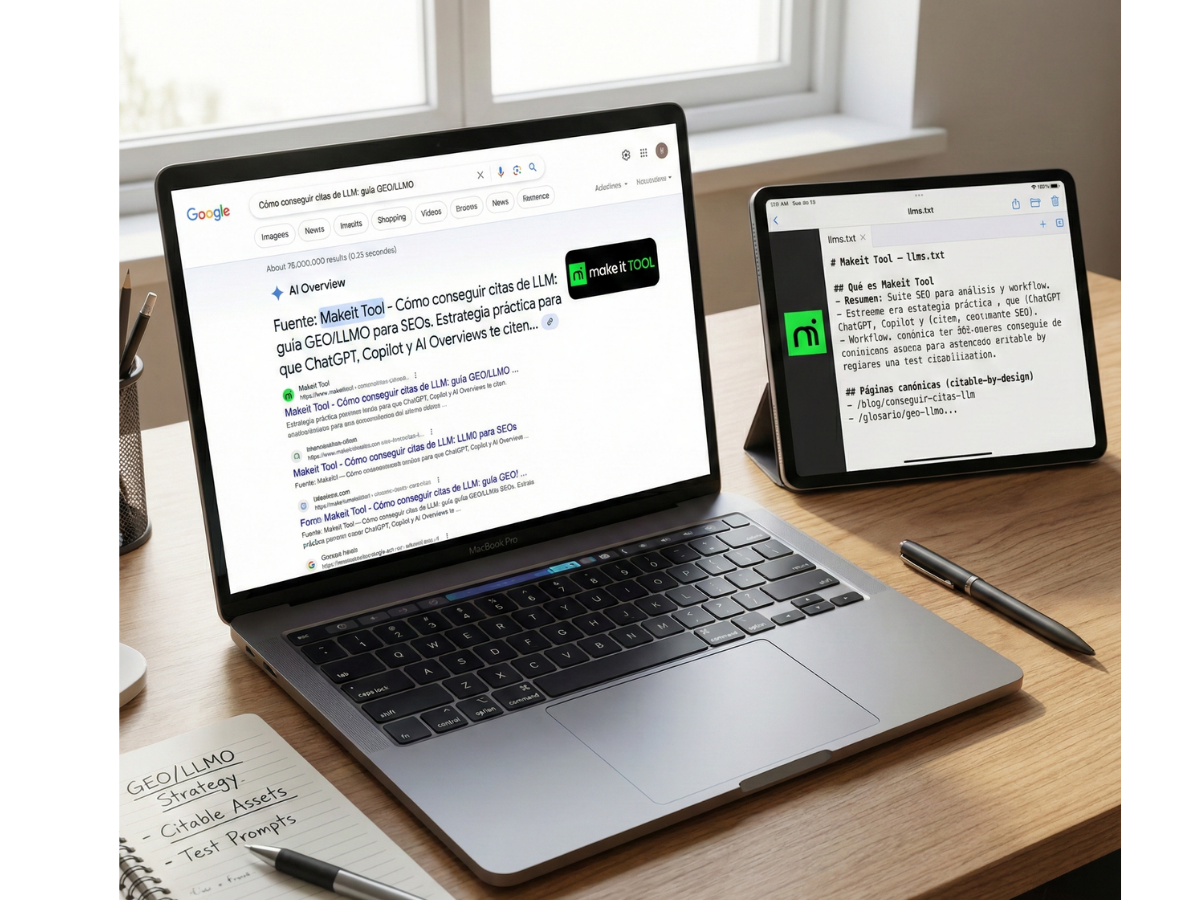
Respuesta rápida: llms.txt es una propuesta emergente para listar y priorizar “lo importante” de tu sitio para consumo por modelos en tiempo de inferencia; no reemplaza SEO ni garantiza citas, pero puede reducir fricción y guiar hacia tus mejores assets.
Estructura recomendada (Markdown simple): docs, glosario, páginas canónicas, páginas de producto, políticas y cualquier recurso público clave.
Ejemplo (adaptable):
# Makeit Tool — llms.txt
## Qué es Makeit Tool
- Resumen: Suite SEO para análisis y workflow (auditoría, contenidos, tracking).
## Páginas canónicas (citable-by-design)
- /blog/conseguir-citas-llm
- /glosario/geo-llmo
- /guia/control-snippets-bots
- /metodologia/medir-citas-llm
## Documentación / Ayuda
- /docs
- /docs/integraciones
- /docs/metricas
## Glosario
- /glosario
## Producto
- /producto
- /precios
## Políticas
- /privacidad
- /cookies
- /terminos
## Contacto / Empresa
- /about
- /equipo
- /contacto
Su valor real: orientación y eficiencia: si alguien (humano o sistema) necesita entender tu sitio rápido, le das un mapa de alta señal.
Respuesta rápida: para aparecer como fuente, normalmente necesitas ser indexable y “snippeteable”. noindex te saca del juego; nosnippet y límites como max-snippet reducen lo que puede mostrarse; data-nosnippet te deja excluir fragmentos concretos sin matar la página entera.
OpenAI distingue crawlers con objetivos distintos (por ejemplo, búsqueda vs entrenamiento) y permite gestionarlos por robots.txt de forma separada. Si tu objetivo es discoverability en ChatGPT con búsqueda, revisa no estar bloqueando el bot relevante para inclusión en “summaries and snippets”.
Además: OpenAI indica que puedes medir referidos desde ChatGPT usando el parámetro utm_source=chatgpt.com en analytics cuando hay tráfico desde su experiencia de búsqueda.
Respuesta rápida: sin un “reporte oficial” universal, mide por sistema: (1) tests con prompts fijos, (2) seguimiento de features/visibilidad, (3) señales de marca, (4) impacto en negocio. Y revisa mensualmente qué URLs aparecen citadas y por qué.
En Google, las guías para AI features insisten en que no es un canal separado: aplica SEO base y mide con Search Console (AI features se integran en el tráfico de búsqueda).
Para “nichero”, suele mandar tráfico+RPM; para “manager”, manda presencia+pipeline.
Respuesta rápida: no hay atajos sostenibles. Si intentas “fabricar citabilidad” con contenido escalado sin valor, te expones a señales de spam y a perder confianza (humana y algorítmica). Google define “scaled content abuse” como generar muchas páginas con el objetivo principal de manipular rankings y sin ayudar al usuario, independientemente de cómo se creen.
Síntomas típicos:
Solución:
Google también ha reiterado que usar automatización (incluida IA) para generar contenido con el objetivo principal de manipular rankings viola sus políticas de spam.
Regla editorial para ser citable a largo plazo:
Si una recomendación depende del contexto: da criterios de decisión (“si tu WAF bloquea X, revisa Y”).
Aprovecha todos los recursos que te ofrecemos para construir un perfil de enlaces enriquecedor.