
How to get LLM citations and become a “citable” entity
If you're already “in the league” (strong EEAT, cluster architecture, performance, healthy tracking), your bottleneck isn't usually “ranking”: it's being chosen as a source and being remembered as an entity. The real objective in GEO/LLMO is not just to appear: it is to appear cited, on a recurring basis, when an AI constructs a response and needs reliable evidence. A quote is a prize for clarity, verifiability and consistency. You already do the rest (technical, internal links, content): here we fine-tune what makes a platform select you as “evidence” and not as “filler”.
Low-code tools are going mainstream
Purus suspended the ornare non erat pellentesque arcu mi arcu eget tortor eu praesent curabitur porttitor ultrices sit sit amet purus urna enim eget. Habitant massa lectus tristique dictum lacus in bibendum. Velit ut Viverra Feugiat Dui Eu Nisl Sit Massa Viverra Sed Vitae Nec Sed. Never ornare consequat Massa sagittis pellentesque tincidunt vel lacus integer risu.
- Vitae et erat tincidunt sed orci eget egestas facilisation amet ornare
- Sollicitudin Integer Velit Aliquet Viverra Urna Orci Semper Velit Dolor Sit Amet
- Vitae quis ut luctus lobortis urna adipiscing bibendum
- Vitae quis ut luctus lobortis urna adipiscing bibendum
Multilingual NLP Will Grow
Mauris has arcus lectus congue. Sed eget semper mollis happy before. Congue risus vulputate neunc porttitor dignissim cursus viverra quis. Condimentum nisl ut sed diam lacus sed. Cursus hac massa amet cursus diam. Consequat Sodales Non Nulla Ac Id Bibendum Eu Justo Condimentum. Arcus elementum non suscipit amet vitae. Consectetur penatibus diam enim eget arcu et ut a congue arcu.

Combining supervised and unsupervised machine learning methods
Vitae Vitae Sollicitudin Diam Sede. Aliquam tellus libre a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
- Dolor duis Lorem enim Eu Turpis Potenti Nulla Laoreet Volutpat Semper Sed.
- Lorem a eget blandit ac neque amet amet non dapibus pulvinar.
- Pellentesque non integer ac id imperdiet blandit sit bibendum.
- Sit leo lorem elementum vitae faucibus quam feugiat hendrerit lectus.
Automating customer service: Tagging tickets and new era of chatbots
Vitae Vitae Sollicitudin Diam Sede. Aliquam tellus libre a velit quam ut suscipit. Vitae adipiscing amet faucibus nec in ut. Tortor nulliquam commodo sit ultricies a nunc ultrices consectetur. Nibh magna arcu blandit quisque. In lorem sit turpis interdum facilisi.
“Nisi consectetur velit bibendum a convallis arcu morbi lectus aecenas ultrices massa vel ut ultricies lectus elit arcu non id mattis libre amet mattis congue ipsum nibh hate in lacinia non”
Detecting fake news and cyber-bullying
Nunc ut Facilisi Volutpat Neque Est Diam Id Sem Erat Aliquam Elementum Dolor Tortor Commodo et Massa Dictumst Egestas Tempor Duis Eget Odio Eu Egestas Nec Amet Suscipit Posuere Fames Ded Tortor Ac Ut Fermentum Odio ut Amet Urna Possuere Ligula Volutpat Cursus Enim Libero Pretium Faucibus Nunc Arcu Mauris Sceerisque Cursus Felis Arcu Sed Aenean Pharetra Vitae Suspended Aenean Pharetra Vitae Suspends Ac.
If you're already doing SEO well, the next leap isn't ranking: it's building evidence and entity for AI to choose you as a source
Starting point: if you already have EEAT + architecture + speed, what's left for LLM appointments?
If basic SEO is OK, there are usually 3 things missing:
- How they “understand” you as an entity: who you are, what are you talking about, with what relationships (product, authors, categories, topics).
- How they “choose you” as evidence: concrete, dense, verifiable and easy to remove parts.
- How they “remember you”: external mentions + stable canonical URLs that the ecosystem can reference over and over again.
What classic SEO already solves (and what it doesn't)
Classic SEO puts you in the competitive set: indexing, thematic relevance, authority, UX, internal linking. Pero The appointments usually require “extras”:
- Quotable blocks (definitions, criteria, tables, checklists) that survive the summary.
- Tests (data, dates, methodology, own examples) instead of generic prose.
- Entity Consistency (name, purpose, authors, policies, “about”, coherent schema).
- External presence (mentions/quotes/editorial) that validates that you are a reference.
What is an “LLM quote” (and why not all platforms quote the same)
An “LLM quote” is visible attribution (link, source card, reference panel) that accompanies a generative response. It's not the same as “being used” internally: what you optimize here is be shown as a source.
- ChatGPT with search: It usually cites when you decide to search for and link to web sources.
- Copilot/search experiences with AI: The quote is part of the product (visibility before the click).
- Google AI features (AI Overviews/AI Mode): think about “SEO + quality”, without looking for tricks; eligibility starts from being indexed and being suitable for snippets.
ChatGPT: when are there appointments and where do they come from
When ChatGPT uses search, select accessible and readable pages, extracts fragments and displays links as sources. In practice, you increase likelihood if you have: (1) crawling allowed for the correct crawler, (2) verifiable content, and (3) a canonical URL that “represents” the concept.
Copilot and search experiences with AI: citation as part of the product
In Copilot, attribution is integrated and designed to allow the user to “see sources” while consuming a summary. That changes the KPI: Your brand can gain presence even if the click goes down; that's why you need to measure visibility/appointments in addition to sessions.
Google AI features: how to think about inclusion without looking for “tricks”
For AI Overviews/AI Mode, the useful guide is: there are no extra technical requirements; apply basic SEO and useful content. To be eligible as a support link, your page must be indexed And to be eligible for snippet. And the snippet controls (nosnippet/data-nosnippet/max-snippet/noindex) also affect what can be displayed.
The 3 levers that most influence getting appointments (when the technical stuff is good enough)
If your baseline is already there, the lever is not “more SEO”, but Increase the probability of selection with a simple mental model:
- Accessible to the right bots.
- Evidence: dense, verifiable content, easy to extract.
- Entity: coherence + external validation.
1) Be accessible to the right bots (without blocking yourself)
If you block tracking or snippets, you exclude yourself of many generative experiences. Before touching Robots/AntiBot/CDN, define your goal: discoverability (quotes/links) vs restrictions.
OpenAI documents crawlers and user-agent controls: you can allow the “search” oriented bot and block the “training” bot independently.
Quick checklist (accessibility):
- Robots.txt: Do I allow the relevant crawler to be cited?
- CDN/WAF: Does it block “new” user-agents by default?
- Answer: Do I return renderable HTML and text in DOM (not just JS)?
- Canonicals: Do I avoid duplicates that dilute signals?
2) Be “evidence”: verifiable, dense and easy-to-extract content
An LLM cites what it can defend. The generic competes for “drafting”; the citable competes for “proof”.
Evidence-first pattern:
- Precise definitions (not “it depends”, but criteria).
- Numbered steps (process).
- Decisions (if A → do B).
- Dated data (what changed and when).
- External sources (for non-obvious claims).
- Own examples (screenshots, templates, mini-cases).
3) Being an “entity”: brand consistency and external mentions that validate you
To be quoted on a recurring basis, you need to be “the X site” at the head of the system:
- Consistent name (brand/product/authors).
- Clear editorial pages (About, team, editorial policy, contact).
- Stable taxonomy (categories/topics).
- Explicit relationship: product ↔ documentation ↔ glossary ↔ guides.
- External mentions: directories, partners, interviews, articles that refer to you (not “linkbuilding by link building”, but citability).
Canonical “citable-by-design” pages: from posts to reference pages
For dating, it usually works best to have 3—6 canonical URLs per topic (reference pages) and use the rest of the cluster as support (cases, long-tail, comparisons, updates). AI needs “a URL that represents the concept” and that is stable.
Canonical set model by topic (example):
- Definition: “What is X” (expanded glossary).
- Methodology: “How to implement X (steps + criteria)”.
- Checklist: “X Audit (Operational List)”.
- Comparison: “X vs Y/when to use what”.
- Policy/standard: “How we measure it/ how we update it”.
“Answer blocks” by section: short answer first, development later
Each H2/H3 should open with 2—3 self-contained (quotable) sentences, and then the development.
Example of a pattern:
Fast response: If you want to be cited, create a canonical URL per concept with definition + criteria + evidence (dates and sources), and link to it from the entire cluster.
Development: cases, nuances, implementation, examples.
Decision tables and checklists: the format that best “survives” the summary
Operating table (template that you can adapt):
Evidence and update: dates, sources and visible 'last review'
A generative system penalizes (even if implicitly) what smells “old” or “unverifiable”.
Recommendations:
- In facts that change: date and source.
- A visible block: “Updated on...” + 2—3 gearbox bullets.
- Avoid absolutes (“always”, “guaranteed”).
- If something is a hypothesis: state it and explain how to validate it.
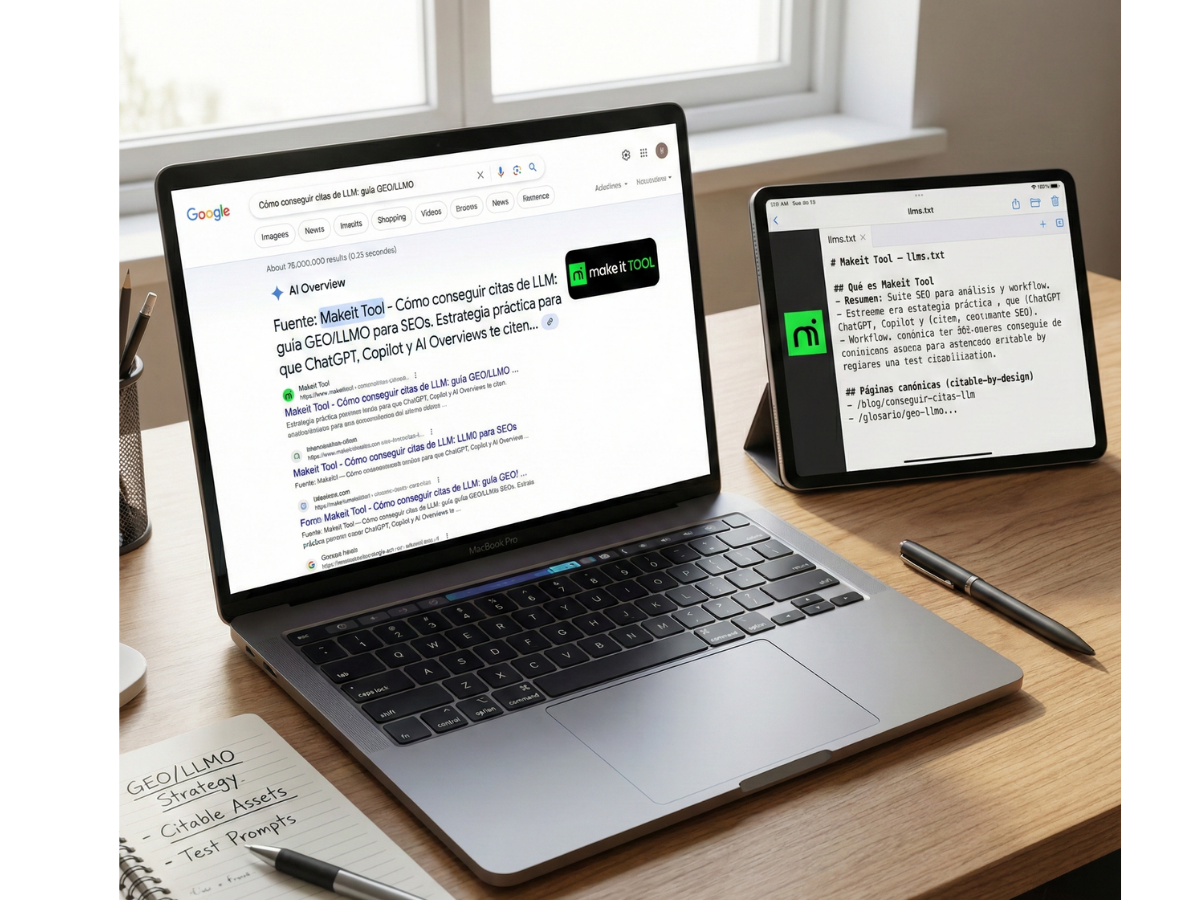
llms.txt: when to use it and what it can bring (without myths)
Fast response: llms.txt is an emerging proposal to list and prioritize “what's important” of your site for consumption by inference time models; it doesn't replace SEO or guarantee citations, but it can reduce friction and guide you to your best assets.
What to include in llms.txt for a SaaS SEO (Makeit Tool)
Recommended structure (Simple Markdown): docs, glossary, canonical pages, product pages, policies, and any key public resource.
Example (adaptable):
# Makeit Tool — llms.txt
## Qué es Makeit Tool
- Resumen: Suite SEO para análisis y workflow (auditoría, contenidos, tracking).
## Páginas canónicas (citable-by-design)
- /blog/conseguir-citas-llm
- /glosario/geo-llmo
- /guia/control-snippets-bots
- /metodologia/medir-citas-llm
## Documentación / Ayuda
- /docs
- /docs/integraciones
- /docs/metricas
## Glosario
- /glosario
## Producto
- /producto
- /precios
## Políticas
- /privacidad
- /cookies
- /terminos
## Contacto / Empresa
- /about
- /equipo
- /contacto
What llms.txt DOESN'T do (and why it's still good)
- It doesn't “rank” on its own.
- It doesn't force anyone to quote you.
- It is not a substitute for internal linking, indexing, or quality.
Its real value: orientation and efficiency: If someone (human or system) needs to understand your site quickly, you give them a high-signal map.
Control of snippets and permissions: if you want appointments, don't limit yourself unintentionally
Fast response: to appear as a source, you usually need to be indexable and “snippeteable”. noindex takes you out of the game; nosnippet and limits like max-snippet reduce what can be displayed; data-nosnippet lets you exclude specific fragments without killing the entire page.
How noindex/nosnippet/max-snippet affect visibility and extractability
- Noindex: if you're not indexed, you can't be selected as a support link in AI Overviews/AI Mode experiences.
- Nosnippet: limits the display of a snippet; generally reduces extractability.
- Max-Snippet: Narrow the length of the snippet; useful if you want to allow “short quote” but not a long summary.
- Data-nosnippet: lock specific parts (for example, a premium section) without blocking the rest.
OpenAI robots and crawlers: What to check before blocking
OpenAI distinguishes between crawlers with different objectives (for example, search vs. training) and allows them to be managed separately by robots.txt. If your goal is discoverability in ChatGPT with search, check that you are not blocking the relevant bot for inclusion in “summaries and snippets”.
In addition: OpenAI indicates that you can measure referrals from ChatGPT using the utm_source=chatgpt.com parameter in analytics when there is traffic from your search experience.
Measurement: How to know if you're getting dates (and if it compensates you)
Fast response: without a universal “official report”, it measures by system: (1) tests with fixed prompts, (2) feature/visibility tracking, (3) brand signals, (4) business impact. And check monthly which URLs are cited and why.
At Google, the guidelines for AI features insist that it's not a separate channel: it applies SEO based and measures with Search Console (AI features are integrated into search traffic).
Useful KPIs: share of citations, referred traffic, branded lift and conversion
- Share of citations:% of times you are quoted in a fixed prompt set (by topic).
- Referred traffic: sessions from generative chat/search (e.g., UTM when applicable).
- Branded lift: upload of brand searches/mentions/natural links.
- Conversion: leads/regs attributable to those canonical pages (not just the blog).
For “niche”, it usually sends traffic+RPM; for “manager”, it sends presence+pipeline.
Risks and Boundaries: What NOT to Do to “Force” Dating
Fast response: there are no sustainable shortcuts. If you try to “manufacture citability” with worthless scaled content, you're exposing yourself to spam signals and losing trust (human and algorithmic). Google defines “scaled content abuse” as generating many pages with the main objective of manipulating rankings and without helping the user, regardless of how they are created.
Scaling pages “for LLM” with no real value (signs of spam and loss of trust)
Typical symptoms:
- Thin variants of the same theme (“for LLM”) with little real difference.
- Definitions rewritten without judgment or evidence.
- Programmatic content with no operational utility (no tables, no decisions, no examples).
Solution:
- Consolidate into 1—2 strong canonical ones.
- Add evidence (data, methodology, timestamps, cases).
- Reduce duplication and improve internal links to the canonical one.
Google has also reiterated that using automation (including AI) to generate content with the primary purpose of manipulating rankings violates its spam policies.
Inventing data, “hallucinations” and unverifiable claims
Editorial rule to be citable in the long term:
- Every important factual claim has source or own evidence.
- If you can't support it: formulate it as a hypothesis and add “how to check it”.
If a recommendation depends on the context: give decision criteria (“if your WAF blocks X, check Y”).
analyze backlinks for free
UP TO 23 DATA PER LINK
Take advantage of all the resources we offer you to build an enriching link profile.